Abstract
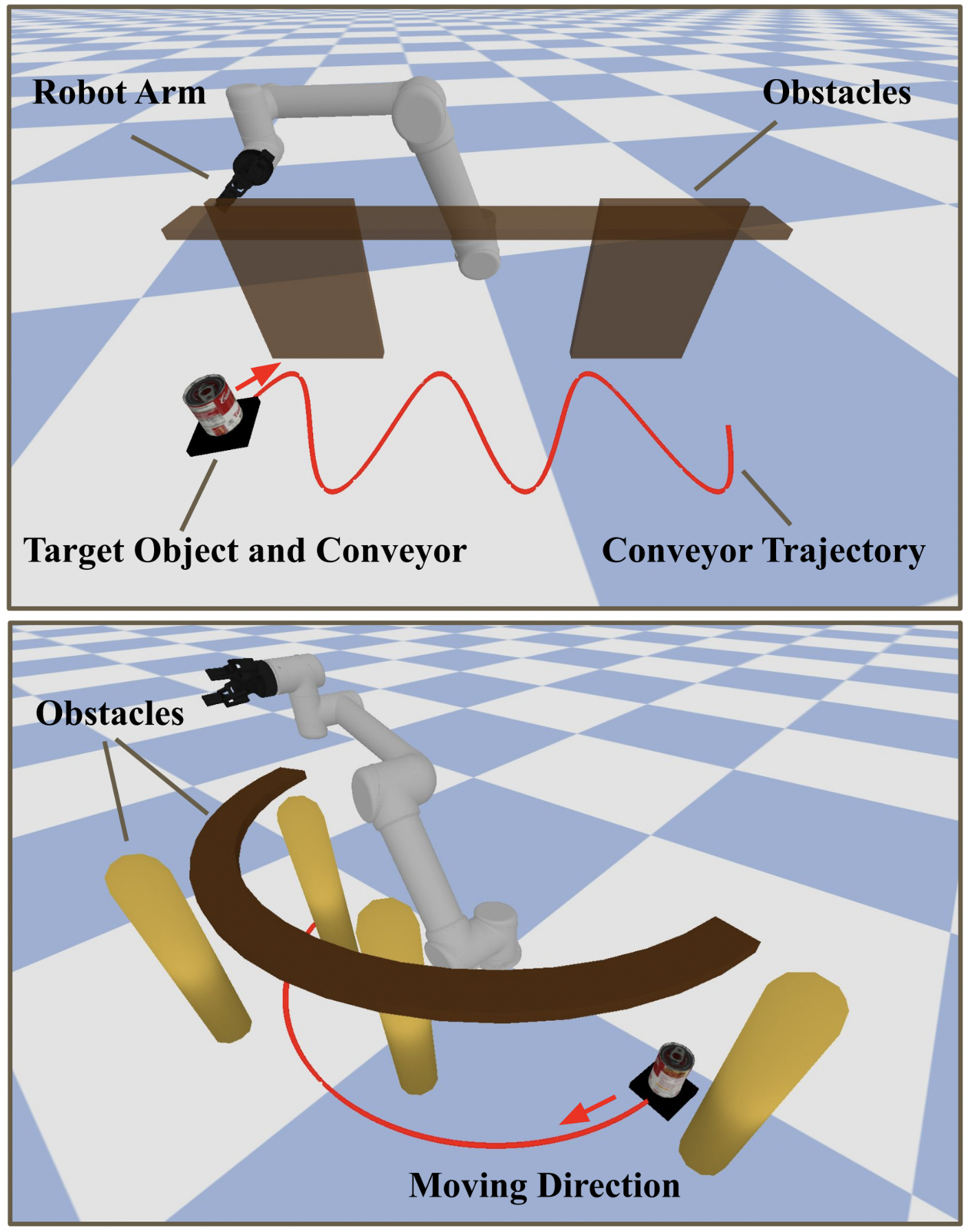 Grasping moving objects is a challenging task that combines multiple
modules such as object pose predictor, arm motion planner, etc. Each
module operates under its own set of meta-parameters, for example, the
prediction horizon in the pose predictor and the time budget for
planning motion in the motion planner. Many previous works assign fixed
values to these parameters either heuristically or through grid search;
however, at different time steps within a single episode of dynamic
grasping, there should be different optimal values for each parameter,
depending on the current scene. In this work, we learn a meta-controller
through reinforcement learning to control the prediction horizon and
time budget dynamically at each time step. Our experiments show that the
meta-controller significantly improves the grasping success rate and
reduces grasping time, compared to baselines whose parameters are fixed
or random. Our meta-controller learns to reason about the reachable
workspace and through dynamically controlling the meta-parameters, it
maintains the predicted pose and the planned motion within the reachable
region. It also generalizes to different environment setups and can
handle various target motions and obstacles.
Grasping moving objects is a challenging task that combines multiple
modules such as object pose predictor, arm motion planner, etc. Each
module operates under its own set of meta-parameters, for example, the
prediction horizon in the pose predictor and the time budget for
planning motion in the motion planner. Many previous works assign fixed
values to these parameters either heuristically or through grid search;
however, at different time steps within a single episode of dynamic
grasping, there should be different optimal values for each parameter,
depending on the current scene. In this work, we learn a meta-controller
through reinforcement learning to control the prediction horizon and
time budget dynamically at each time step. Our experiments show that the
meta-controller significantly improves the grasping success rate and
reduces grasping time, compared to baselines whose parameters are fixed
or random. Our meta-controller learns to reason about the reachable
workspace and through dynamically controlling the meta-parameters, it
maintains the predicted pose and the planned motion within the reachable
region. It also generalizes to different environment setups and can
handle various target motions and obstacles.
Video
This is the supplementary video.